
Implementing TurboQuant in llama.cpp: CUDA Scars and What Actually Ships
3 weeks of porting TurboQuant to CUDA, 5 scars, and what actually ships for document processing on T4 GPUs
Part 1 of 2.
Why We Did This
Hammer.ai runs a industrial research lab hyper focused on regulated domain document understand at extremely efficient margins. Private equity self funded companies like fenero.ai today run document processing pipelines were every token matters. run document processing on commodity GPUs. Hammer.ai look at leveraging a simpler stack is Gemma 3 4B on NVIDIA T4s ($0.35/hr) for classifying invoices, extracting dates, and normalizing structured data. Today, KV cache eats 136MB per conversation at 8K context. Google Research's TurboQuant paper (arXiv:2504.19874) promised to compress that by 4-5x with "near-zero quality loss."
We spent a tremendous amount of time porting it to CUDA for Fenero.ai's useless, integrating it into llama.cpp's flash attention, and benchmarking it privately on our actual workloads. This post is about what we built, what broke, what we learned about CUDA the hard way, and what actually ships.
What TurboQuant Does (The Elegant Part)
The idea is beautiful. Before compressing each 128-number KV cache vector:
Scramble it with a Walsh-Hadamard Transform (WHT) — a fast, reversible mixing operation that turns any distribution into a bell curve
Compress each value to 3 bits using 8 pre-computed optimal buckets (Lloyd-Max centroids)
Unscramble at attention time
Because every vector looks statistically identical after step 1, one fixed set of compression buckets works for any model, any layer, any input. No calibration data needed. The math is clean: WHT is orthogonal (preserves dot products), so you can compute attention in the "scrambled" space and only unscramble the final output.
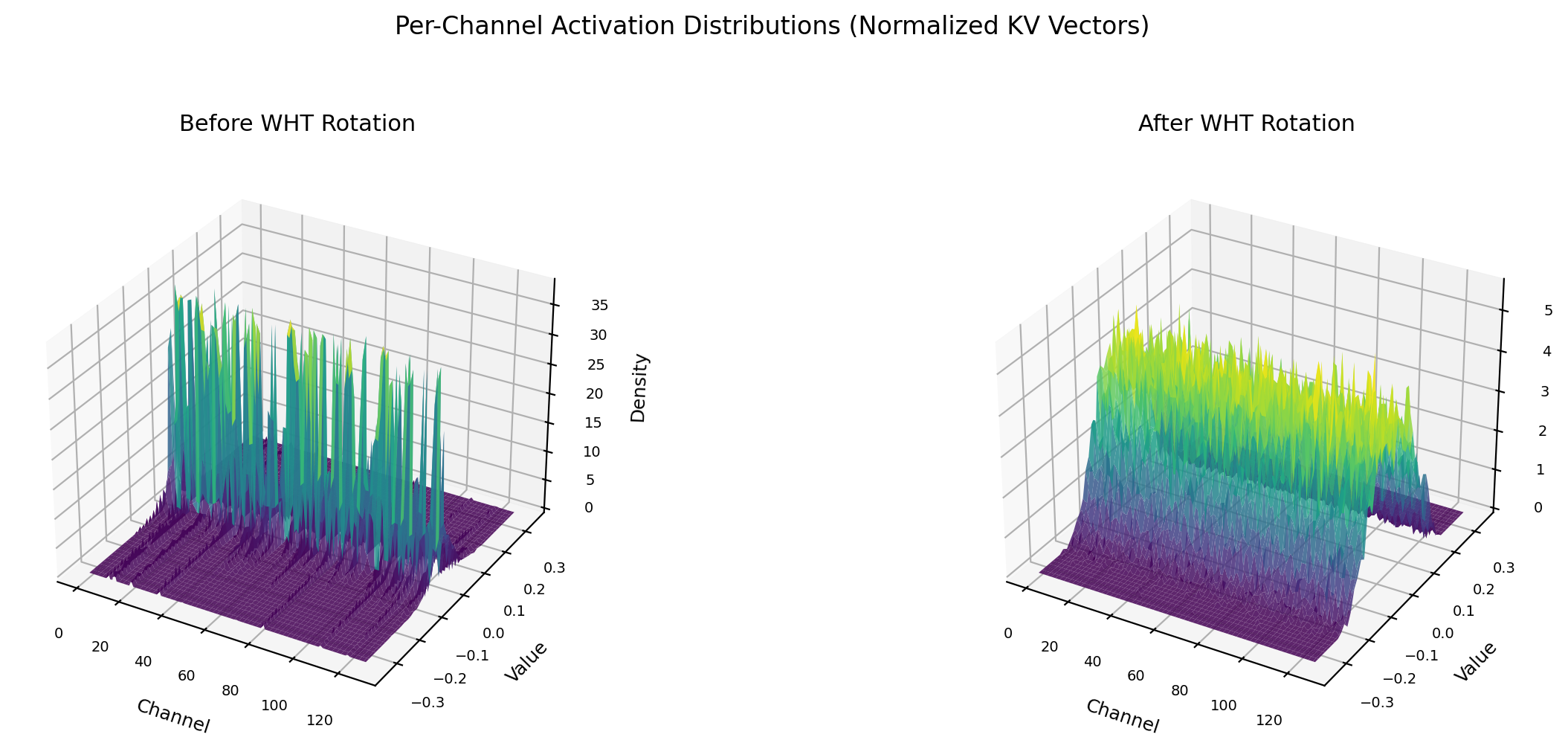
Left: raw KV activations have outlier channels that spike 30x above the rest. Right: after WHT rotation, every channel is Gaussian with identical variance. One codebook fits all.
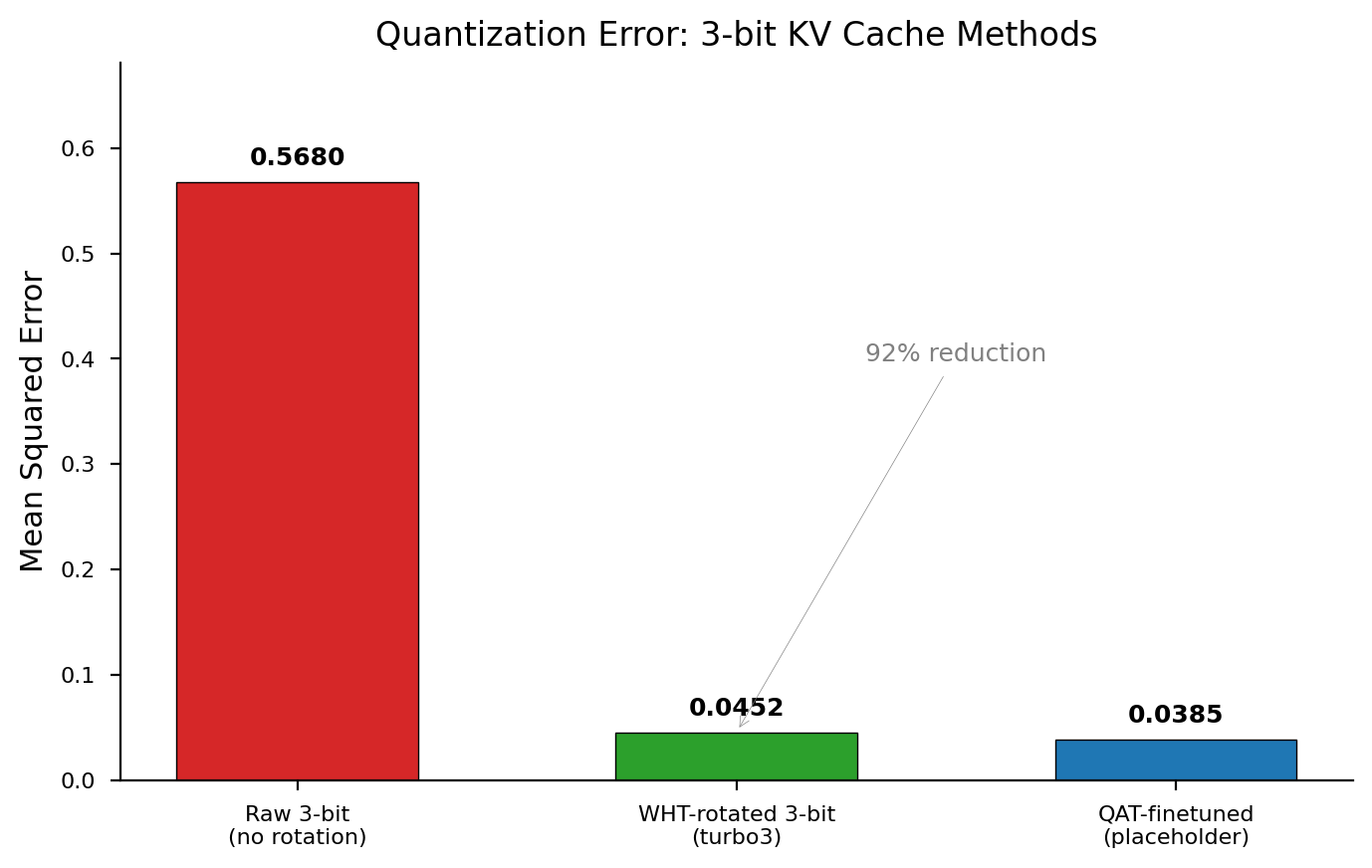
The payoff: 92% reduction in quantization error. The remaining 0.045 MSE is what causes the quality gap we spend the rest of this post trying to close.
What We Built
Our implementation adds three new KV cache types to a llama.cpp fork:
| Type | Bits/value | Compression | Method |
|---|---|---|---|
| turbo3 | 3.5 | 4.6x | 8 Lloyd-Max centroids after WHT |
| turbo4 | 4.25 | 3.8x | turbo3 + 1-bit QJL residual |
| turbo_split2 | 2.5 | 6.4x | Outlier-aware: 32 channels @ 3-bit, 96 @ 2-bit |
This required modifying ~25 files: block struct definitions, CUDA quantize/dequant kernels, flash attention integration (V dequant + K dot product), type registration across the ggml tensor library, graph-side WHT rotation, and server CLI parsing.
The Key Engineering Challenge: Warp-Cooperative FWHT
The WHT "unscramble" during flash attention is the hard part. The naive approach (one thread loads all 128 values, runs the butterfly) allocates float[128] per thread — 128 registers. On a T4's Turing SM (65,536 registers total), NVCC has no choice but to spill to L1-backed local memory. Result: 47 tokens/s collapses to 2 tokens/s at 8K context — a 24x slowdown.
We use a warp-cooperative FWHT: 32 GPU threads each hold 4 values, communicate via __shfl_xor_sync warp shuffles. Zero shared memory, zero local memory, 28 shuffles total.
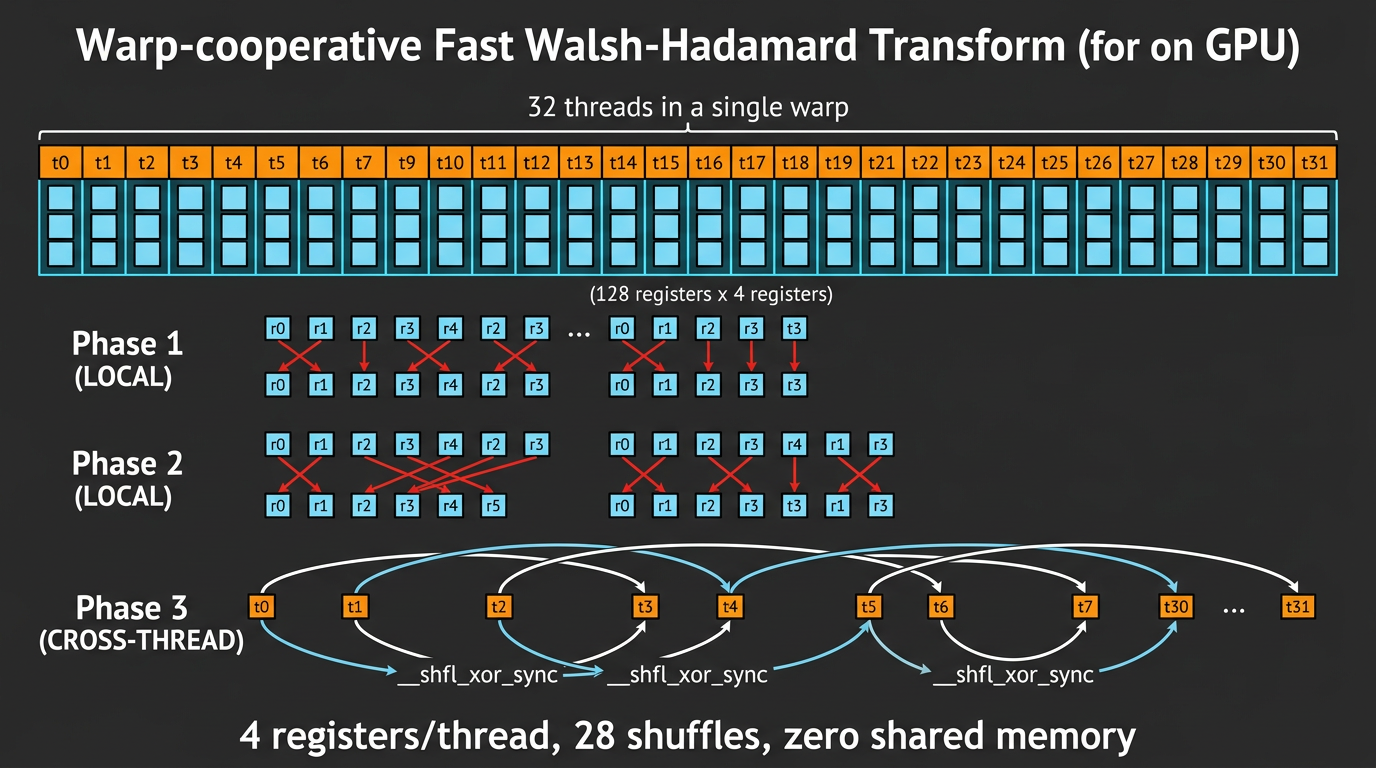
The warp-cooperative FWHT distributes 128 elements across 32 threads (4 registers each). Local butterflies happen inside each thread. Cross-thread butterflies use __shfl_xor_sync — no shared memory, no spilling.
This recovered full speed: 37 tokens/second on T4, flat across context lengths.
What We Measured
We tested on a custom benchmark suite: 35 prompts across classification, extraction, arithmetic, reasoning, and verification. All measurements on Tesla T4, temperature=0, max_tokens=16.
| Model | Cache | Score | Bits/val | Compression |
|---|---|---|---|---|
| Gemma 3 4B (ollama fp16) | fp16 | 24/35 | 16 | 1x |
| Gemma 3 4B (our server) | q8_0 | 25/35 | 8 | 2x |
| Gemma 3 4B | turbo4 | 15/35 | 4.25 | 3.8x |
| Gemma 3 4B | turbo3 | 12/35 | 3.5 | 4.6x |
| Gemma 3 4B | turbo_split2 | 8/35 | 2.5 | 6.4x |
| Gemma 4 E4B | q8_0 | 21/35 | 8 | 2x |
| Gemma 4 E4B | turbo4 | 10/35 | 4.25 | 3.8x |
The good news: Document classification (invoice/receipt/contract/letter/resume/medical) scores 7/7 across every turbo configuration. The first token is almost always correct.
The bad news: Everything requiring coherent multi-token generation degrades. Extraction ("What's the invoice number?"), arithmetic ("17*23?"), and reasoning tasks produce 1-2 correct tokens then drift into multilingual garbage.
Lessons learned
These aren't bugs in TurboQuant — they're scars from implementing the math in CUDA and integrating it into llama.cpp's existing architecture. Each one burned real debugging time.
Scar 1: Two FWHTs, Two Normalization Conventions
We have two FWHT implementations:
turbo_fwht_128: per-thread version (one thread, 128-element array) used in the quantize kernelturbo4_warp_fwht: warp-cooperative version (32 threads, 4 elements each) used in flash attention
The per-thread version already includes 1/sqrt(128) normalization — making the WHT rotation orthogonal. The warp version does NOT normalize; the caller applies it separately.
When we tried to "fix" the rotation by adding normalization to the forward path, we accidentally double-normalized — dividing every value by 128 instead of sqrt(128). Quality dropped from 15/35 to 0/35.
Lesson: When you have two implementations of the same math, document which normalization convention each uses.
Scar 2: The QJL Scale Factor
turbo4 adds a 1-bit QJL (Quantized Johnson-Lindenstrauss) residual correction on top of 3-bit centroids. The paper's formula:
$$\tilde{x}_{qjl} = \frac{\sqrt{\pi/2}}{d} \cdot \gamma \cdot S^T \cdot \text{qjl}$$
Our structured S (Hadamard with random signs) has the same row norms as the paper's Gaussian S. But the warp-cooperative FWHT doesn't normalize, so the magnitude was sqrt(d) larger than expected. We had an extra 1/sqrt(128) factor making the QJL correction 11.3x too weak.
Found it by tracing Algorithm 2 line-by-line against our code. Fixed it. Quality didn't change — the 3-bit centroid quality dominates. The QJL correction is theoretically important (unbiased inner product estimator) but practically invisible.
Lesson: When porting paper math to GPU kernels with different normalization conventions, trace through the full pipeline with actual numbers. Pen-and-paper verification catches scale factors that unit tests miss.
Scar 3: __constant__ Memory Across Compilation Units
CUDA __constant__ variables with static linkage in header files get duplicated per compilation unit. Our flash attention uses template specialization — each KV cache type pair compiles as a separate .cu file. When we added channel permutation lookup tables as __constant__ static arrays in a header, the FA template instances got their own copies with uninitialized data.
The quantize kernel (in turbo-quant.cu) got the correct values. The FA dequant kernels (in fattn-vec-instance-*.cu) got zeros. Result: garbage output with no crash or error.
Fix: Use constexpr arrays inside __device__ __forceinline__ functions:
static __device__ __forceinline__ bool turbo_split2_is_outlier(int ch) {
constexpr int T[128] = { /* values */ };
return T[ch] != 0;
}
The compiler embeds the data in each kernel's instruction stream — no device memory allocation, no cross-CU issues.
Lesson:
__constant__memory is device-side global state with compilation-unit-scoped initialization. For small lookup tables (<1KB), embed them in inline device functions instead.
Scar 4: Multiple Dequant Paths
llama.cpp has at least three code paths that read quantized KV cache values:
Flash attention (
fattn-common.cuh) — the hot path during generationBlock dequantize (
convert.cu) — non-FA fallback and model conversionGet rows (
getrows.cu) — used by some attention implementations
When we added channel permutation for outlier-aware splitting, we updated the FA path but forgot convert.cu and getrows.cu. The quantize stored channels in permuted order. FA read them back correctly. But any non-FA code path read them in the wrong order: 0/35 with profiled permutation, even though FA alone was correct.
Lesson: In a codebase with multiple paths to the same data, grep for ALL consumers before changing the data layout.
Scar 5: Flash Attention Template Parameters
The FA vec kernel launches with 128 threads organized as dim3(32, 4) — 4 warps of 32 threads. The V dequant function receives threadIdx.x (0-31 within a warp) as the lane index. We worried that nthreads_V and V_rows_per_thread template parameters might cause turbo4's 128-element blocks to be read incorrectly. After tracing through the template dispatch, we confirmed: V_rows_per_thread=4 for all turbo types, and each warp independently processes a full 128-element group. But the debugging took 2 hours of reading template metaprogramming.
Lesson: Before adding a new quantization type to llama.cpp, read the full FA dispatch chain:
ggml_cuda_flash_attn_ext_vec->flash_attn_ext_vec->get_dequantize_V-> your function. Print the actual template parameters for your type.
What the Paper's Claims Mean in Practice
The TurboQuant paper is excellent research. Their claims are accurate — for their setup:
"Quality neutrality at 3.5 bits" — on Llama 3.1 8B with LongBench. Llama is a larger model (8B vs our 4B) with more redundancy. LongBench tests long-context understanding, not short-prompt extraction.
"Outlier-aware splitting at 2.5 bits" — the paper uses 32 channels at 3-bit + 96 at 2-bit. We implemented this exactly. It works on Llama. It doesn't work on Gemma 3 4B for short prompts — the 2-bit codebook (4 centroids) is too coarse for 75% of channels on a small model.
"QJL residual provides unbiased inner product estimation" — mathematically true. Practically unmeasurable at 3-bit base quality. The 1-bit correction is drowned out by the 3-bit centroid error.
None of this is the paper's fault. They clearly state their experimental setup. The lesson is about generalization: paper results on Model A with Benchmark B don't guarantee the same on Model C with Benchmark D.
Channel Variance: Real, Model-Specific, and Less Useful Than You'd Think
We added per-channel variance profiling to the quantize kernel (atomicAdd after WHT rotation, 2000 samples):

Before WHT: a few outlier channels dominate (max variance 0.25). After WHT: 30x more uniform (max 0.0085). But "more uniform" is not "perfectly uniform."
Gemma 3 4B: Max/min variance ratio = 1.77x. High-variance channels cluster at positions 64-127 (deterministic WHT sign structure, seed=42).
Gemma 4 E4B: Ratio = 1.56x. High-variance channels are scattered — no clustering.
Cross-model overlap: Only 8 of 32 top channels are shared between the two models.
This confirms the paper's recommendation for per-model outlier profiling. But the practical impact is limited: even with perfect outlier selection, 2.5-bit quantization doesn't work for our tasks on these models. The bottleneck isn't WHICH channels get more bits — it's the total bit budget.
What Actually Ships
Document classification at 3-bit + GPU process pooling = 3x cheaper inference.
We combine turbo3 KV cache (4.6x compression) with NVIDIA cuda-checkpoint (23ms GPU freeze/thaw). This lets us run 3 Gemma 3 4B instances on a single T4, each ready to classify documents in under 500ms.
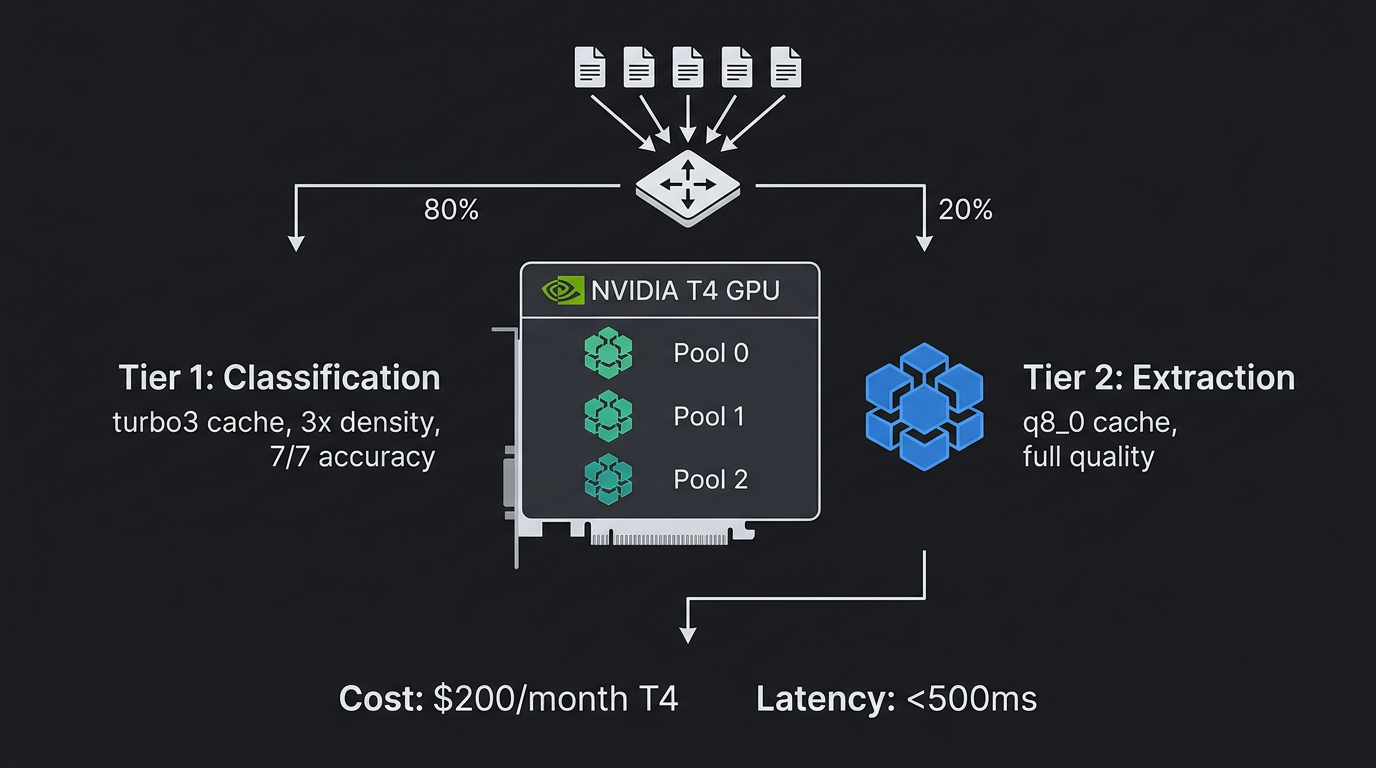
The production architecture is two-tier:
Tier 1 (classification): turbo3 cache, cuda-freeze pool, 3x density. 7/7 accuracy on document type classification.
Tier 2 (extraction): q8_0 cache, single instance, full quality. Handles invoice number extraction, date parsing, line item listing.
Route: classify cheap (Tier 1), extract only from relevant pages (Tier 2). 80% of inference is classification — 3x savings on the dominant workload.
Cost: \(200/month T4. 3 concurrent instances. Document classification at ~\)0.001 per page.
What We'd Do Differently
Start with the paper's exact model. We tested Gemma because it's what we deploy. If we'd started with Llama 3.1 8B (the paper's model), we'd have gotten positive results faster and THEN investigated model sensitivity.
Build a proper benchmark before writing CUDA. We built the benchmark suite midway through. Having it from day 1 would have caught quality issues earlier.
Don't implement QJL until you've validated 3-bit. We spent significant time on the warp-cooperative QJL FWHT before discovering that the base 3-bit quality is the bottleneck. Should have tested turbo3 exhaustively first.
Profile the data, not just the code. Channel variance profiling was the most valuable 20 lines of CUDA we wrote. It took 3 weeks to think of doing it.
What's Next
The 10-point quality gap between q8_0 (25/35) and turbo4 (15/35) isn't in the quantizer — it's in the model's activations. Can we teach the model to produce KV values that survive 3-bit compression?
In Part 2, we try quantization-aware fine-tuning: 4 training iterations, 6 more CUDA scars, a synthetic data teacher, and the honest answer about how far fine-tuning closes the gap.
The TurboQuant paper is at arXiv:2504.19874. The warp-cooperative FWHT technique is described in our companion paper.
Kartik Thakore — Hammer LabsContact: kartik at multiversal.ventures